The C preprocessor's Worst abuse - (IOCCC winner, 1986)
Hi guys, today I am going to tell you about the winner of the C preprocessor worst abuse in the 3rd International Obfuscated C Code Contest (IOCCC) of 1986. I know you're like, "OMG!, what in heavens name is that?" Of course, I was just like you when I first heard of it. I wondered what it was and I had rolled my eyes up and sighed "what again, what have I not heard about the mighty Processor?" But as a cat that I was, (I mean very curious), I had spun up my favorite web browser(don't worry but its not Opera or the mini of it), and dug deeper to learn more about this awesome title. Guess what I found? You guessed wrong, sorry but I guessed same thing. I thought it was all about the computer Processor. I was wrong. It turned out it was just a C code, a program actually. Terrifying and scary so please grab your bullet proof because this is going to be a tough shot. Today, we are going to try and understand how the code or program works, step by step.
Introduction
And the winner is Jim Hague, the creator of almost undecipherable morse encryptor called "The C preprocessor worst abuse". The International Obfuscated C Code Contest is actually an annual computer programming contest specifically for creating obfuscated C code and the winner was the C preprocessor worst abuse in the 3rd International Obfuscated C Code Contest (IOCCC) of 1986. The goal of IOCCC contest is to create the most obscure C program. The competition allowed computer training competitors to have their creations to be evaluated by some anonymous panel of judges. The emerging winners were awarded in a number of areas which included "worst abuse of the C preprocessor," or "most erratic behavior." Winners had their names announced on the IOCCC website as prize for their success.
First, lets take a look at what the code looks like: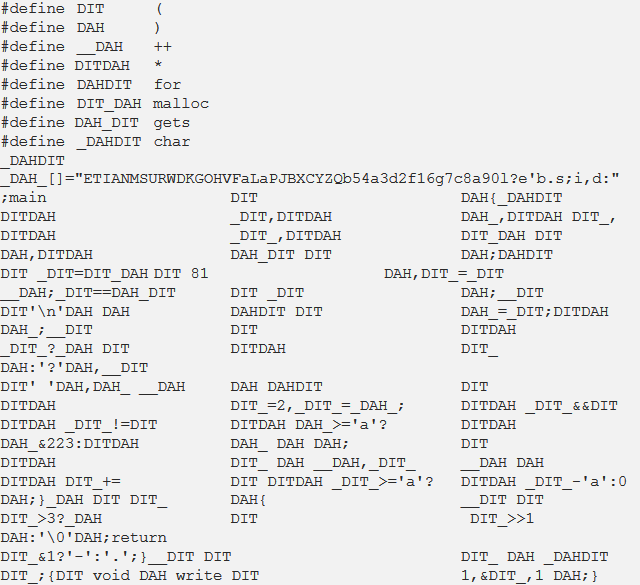
What the Code/Program does
Obfuscated code is a source or machine code that is deliberately written to be difficult for humans to understand. Obfuscated code can be used for a variety of reasons, and there are many pros and cons to the practice. The benefits can be security and code optimization, and some disadvantages may be maintenance and debugging. So the code is an (almost) undecipherable morse encryptor or obfuscation code.
How it works
A quick look at the code and we notice the multiple declarations of macros using #define keyword with repetitive use of DIT and DAT variations in every other places. If you try to compile the code, you will get a bunch of compiler warnings and errors. This is because there are uses of malloc and gets in the code which requires the C standard libraries and are not included yet so the compiler is not too happy about that.
In the first eight lines the autor started defining a new values for character like (, ), ++, * and functios like for, malloc, gets, char. So after that, he will use the new statement for his values instead of the normal character. We could also see two defined functions and a main function that uses these two latter functions. Also, a declare a global or static String call _DAH_. Inside, the main function we have a char pointers declaration and a short list of for loops which translate de characters.
The code/program actually collects user input, a string (remember our gets()), to be precise and obfuscates it. So we can input something like Hello, Holberton and on the Morse Code Translator, the result will be .... . .-.. .-.. --- --..-- / .... --- .-.. -... . .-. - --- -.
Ta dah!!
Step by step "de-obfuscation" for readability
After inclusion of the standard C libraries and de-obfuscation to make the code readable, the code should look something like below. Take a look:
#include
#include
#include
#include
#define DIT (
#define DAH )
#define __DAH ++
#define DITDAH *
#define DAHDIT for#define DIT_DAH malloc
#define DAH_DIT gets
#define _DAHDIT char
char morse[]="ETIANMSURWDKGOHVFaLaPJBXCYZQb54a3d2f16g7c8a90l?e'b.s;i,d:";
char translate(int c);
int _putchar(char c);int main(void)
{
char *string, *c, *next, *morsecpy, *gets(char *); for (string = malloc(81), next = string++; gets(string); _putchar('\n'))
{
for (c = string; *c; _putchar(*morsecpy ? translate(*next) : '?'), _putchar(' '), c++)
{
for (*next = 2, morsecpy = morse; *morsecpy && (*morsecpy != (*c >= 'a' ? *c & 223 : *c)); (*next)++, morsecpy++)
{
if (*morsecpy >= 'a')
*next += *morsecpy - 'a';
else
*next += 0;
}
}
} return (0);
}char translate(int c)
{
if (c > 3)
_putchar(translate(c >> 1));
else
_putchar('\0'); if (c & 1)
return ('-');
else
return ('.');
}int _putchar(char c)
{
return (write(1 , &c , 1));
}
Step 1: replacing the macros
To understand the logic of the code we have to replace every macro with its corresponding defined value, get rid of the unnecessary white space and try to indent the code.
Step 2: replacing the names of the functions and variables
Next, we can give the functions, variables and arrays meaninful names like the _DAH_[], which is a character array, or _DIT. e.g.
- _DIT will become string
- DAH_ will become c
- DIT_ will become next
- _DAH_[] will become morse
- _DIT_ will become morsecpy
__DIT() did the same as the library function putchar(), which prints a character to the standard output, our terminal window. Therefore, we rename it to _putchar(). Then, we change the name of the function _DAH() to translate(). This is what translate() function does.
char translate(int c)
{
if (c > 3)
_putchar(translate(c >> 1));
else
_putchar('\0');if (c & 1)
return ('-');
else
return ('.');
}
This part is tricky to understand, but it's the key to our morse translation. That's why we named it "translate".
Similarly, the putchar() function has a duty of printing out whatever we want to print out just like the standard library putchar() function. So we add a parameter c of type char, which is the character we want to print.
int _putchar(char c)
{
return (write(1 , &c , 1));
}
Step 3: the main() function
This is by far the hardest part of the code to understand, it contains many loops and a nested loop. It also contains some pointers variables.
- morse[]: string that contains all the characters we are going to compare our input string with
- *string: pointer to the string we sill get from the standard input, aka the keyboard, that we will loop through, character by character
- *c: pointer to the string that holds the current character in the input string
- *next: pointer to a placeholder character
- *morsecpy: pointer to string that contains the characters of morse and that will be modified
- *gets: this is the standard library function that gets a string from the standard input
The first loop
for (string = malloc(81), next = string++; gets(string); _putchar('\n'))
What this loop does is that it takes a string and executes the following code and then print a new line. This takes a new string from the standard input.
The second loop
for (c = string; *c; _putchar(*morsecpy ? translate(*next) : '?'), _putchar(' '), c++)
This loop prints the morse symbols for each letter. This loop will run entirely for every iteration of the previous loop.
The last nested loop
for (*next = 2, morsecpy = morse; *morsecpy && (*morsecpy != (*c >= 'a' ? *c & 223 : *c)); (*next)++, morsecpy++)
This loop will run for every iteration of the previous loop.
The code inside the loops
if (*morsecpy >= 'a')
*next += *morsecpy - 'a';
else
*next += 0;
This code is executed for every iteration of the last loop. So what happens here is that if the character in morsecpy is lowercase, then we add the ASCII value of *morsecpy - 'a' to next, otherwise it doesn't add anything to next.
That's all folks. Have fun and enjoy coding.




Advertisement
Advertisement
Advertisement
-
 The C preprocessor's Worst abuse - (IOCCC winner, 1986)
The C preprocessor's Worst abuse - (IOCCC winner, 1986) -
 Creating and Consuming Static Library in C
Creating and Consuming Static Library in C -
 What happens when you type gcc main.c
What happens when you type gcc main.c -
 How object and class attributes work in Python
How object and class attributes work in Python -
 Difference between a hard link and a symbolic link
Difference between a hard link and a symbolic link -
 The differences between static and dynamic libraries
The differences between static and dynamic libraries -
 How to Create MySQL Database using phpMyAdmin
How to Create MySQL Database using phpMyAdmin -
 How integers are stored in memory using two's complement in digital computers
How integers are stored in memory using two's complement in digital computers