Machine Learning
Introduction
When you type "Machine Learning" or "what is machine learning?" into a Google search or any search engine, a pandora's box of research papers, discussions, articles, blogs, forums, academic research, including false information that show up for you to read can be overwhelming. Depending on whom you ask, the concept of machine learning may have a slightly different definitions. There are a lot of definitions and meanings and if one is not careful what you read, you might find yourself more confused and better off not reading at all. The aim of this article is to simplify the definition and make understanding of machine learning a little bit less confusing. We will take a look at a few definitions from around the web and then put them together in a simpler definition. So lets get started.
What is Machine Learning?
Wikipedia definition:
Machine learning (ML) is the study of computer algorithms that improve automatically through experience. Read Here.
MIT Technology Review definition:
Machine-learning algorithms use statistics to find patterns in massive* amounts of data. And data, here, encompasses a lot of things; numbers, words, images, clicks, what have you. If it can be digitally stored, it can be fed into a machine-learning algorithm. Read Here.
spotlightmetal.com definition
Machine Learning is a sub-area of artificial intelligence, whereby the term refers to the ability of IT systems to independently find solutions to problems by recognizing patterns in databases. In other words: Machine Learning enables IT systems to recognize patterns on the basis of existing algorithms and data sets and to develop adequate solution concepts. Therefore, in Machine Learning, artificial knowledge is generated on the basis of experience. Read Here.
My definition
From the above definitions from around the web, we could see that they are all trying to define the same thing but in different ways. I am not going to create a new definition for machine learning. I am going to make those definitions from around the web simple and straight forward to the point. No kidding around.
What is Machine Learning?
"Machine Learning is a way programmers get computers to learn and act like humans do."
Simple and straight to the point.
How I Arrived at My Definition
I dug and combed the web to find over 10 practical definitions but below are five from very reputable sources: (Number one is my favorite.)
- 1. Machine Learning is the science of getting computers to learn as well as humans do or better. Dr. Roman Yampolskiy, University of Louisville
- 2. "Machine learning is the science of getting computers to act without being explicitly programmed." - Stanford
- 3. "Machine learning is based on algorithms that can learn from data without relying on rules-based programming."- McKinsey & Co.
- 4. "Machine learning algorithms can figure out how to perform important tasks by generalizing from examples." - University of Washington
- 5. "Machine Learning at its most basic is the practice of using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world." - Nvidia
How to Get Machines to Learn
I hate beating around the bush. The shortest of any answer you would ever get:
Algorithms
As simple as that may sound, trust me, there is more to it than just algorithms.
From my deduced definition above, I intentionally mentioned programmers since most definitions of machine learning, even those of Professors and higher institutions, do not make mention of "programmers" or "software engineers". They make machine learning sound "magical" as though machines or computers just start learning on their own. My grannies are never going to understand this concept if I don't explain to them exactly what these other definitions were trying to say. Okay, so how do programmers or software engineers get machines (computers, to be more precise) to learn.
We(programmers or software engineers) feed "algorithms", which are sets of rules used to help computers perform problem-solving operations, large volumes of data from which to learn. Generally, the more data a machine learning algorithm is provided the more accurate it becomes.
Oh boy, okay lets go back to beating around the bush. Well, there are different ways and approaches to getting machines or computers to learn. From using basic decision trees to clustering to layers of artificial neural networks (the latter of which has given way to deep learning), depending on what task you're trying to accomplish and the type and amount of data that you have available. This dynamic sees itself played out in applications as varying as medical diagnostics or self-driving cars.
While emphasis is often placed on choosing the best learning algorithm, researchers have found that some of the most interesting questions arise out of none of the available machine learning algorithms performing to par. Most of the time this is a problem with training data, but this also occurs when working with machine learning in new domains.
How Machine Learning Works
Machine learning uses two types of techniques: supervised learning, which trains a model on known input and output data so that it can predict future outputs, and unsupervised learning, which finds hidden patterns or intrinsic structures in input data.
Some Machine Learning Methods
Machine learning algorithms are often categorized as supervised or unsupervised.
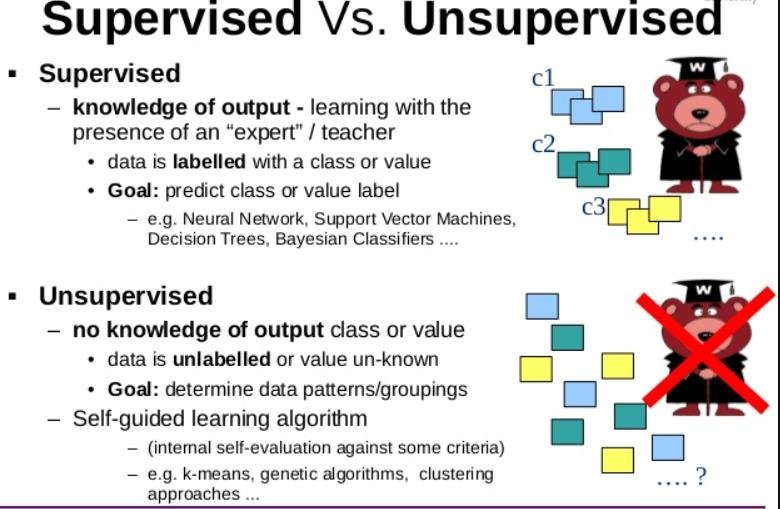
- 1. Supervised machine learning algorithms can apply what has been learned in the past to new data using labeled examples to predict future events. Starting from the analysis of a known training dataset, the learning algorithm produces an inferred function to make predictions about the output values. The system is able to provide targets for any new input after sufficient training. The learning algorithm can also compare its output with the correct, intended output and find errors in order to modify the model accordingly.
- 2. In contrast, unsupervised machine learning algorithms are used when the information used to train is neither classified nor labeled. Unsupervised learning studies how systems can infer a function to describe a hidden structure from unlabeled data. The system doesn't figure out the right output, but it explores the data and can draw inferences from datasets to describe hidden structures from unlabeled data.
- 3. Semi-supervised machine learning algorithms fall somewhere in between supervised and unsupervised learning, since they use both labeled and unlabeled data for training - typically a small amount of labeled data and a large amount of unlabeled data. The systems that use this method are able to considerably improve learning accuracy. Usually, semi-supervised learning is chosen when the acquired labeled data requires skilled and relevant resources in order to train it / learn from it. Otherwise, acquiring unlabeled data generally doesn't require additional resources.
- 4. Reinforcement machine learning algorithms is a learning method that interacts with its environment by producing actions and discovers errors or rewards. Trial and error search and delayed reward are the most relevant characteristics of reinforcement learning. This method allows machines and software agents to automatically determine the ideal behavior within a specific context in order to maximize its performance. Simple reward feedback is required for the agent to learn which action is best; this is known as the reinforcement signal.
What is required to create good machine learning systems?
- 1. Data preparation capabilities.
- 2. Algorithms - basic and advanced.
- 3. Automation and iterative processes.
- 4. Scalability.
- 4. Ensemble modeling.
Key Takeaways in using Machine Learning
- 1. Many times when algorithms don't perform well, it's due a to a problem with the training data (i.e. insufficient amounts/skewed data; noisy data; or insufficient features describing the data for making decisions.
- 2. "Simplicity does not necessarily imply accuracy" - there is (according to Domingo) no given connection between number of parameters of a model and tendency to over-fit.
- 3. Obtaining experimental data should be done, if possible, as opposed to observational data, over which we have no control. For instance, data gleaned from sending different variations of an email to a random audience sampling.
- 4. The more important point is to predict the effects of our actions and not whether we label data causal or correlative.
- 4. The iterative aspect of machine learning is important because as models are exposed to new data, they are able to independently adapt. They learn from previous computations to produce reliable, repeatable decisions and results.
Works Cited
- 1 - http://homes.cs.washington.edu/~pedrod/papers/cacm12.pd
- 2 - http://videolectures.net/deeplearning2016_precup_machine_learning/
- 3 - http://www.aaai.org/ojs/index.php/aimagazine/article/view/2367/2272
- 4 - https://sites.google.com/site/dataefficientml/
- 5 - https://expertsystem.com/machine-learning-definition/
- 6 - https://en.wikipedia.org/wiki/Machine_learning
- 7 - https://www.spotlightmetal.com/machine-learning--definition-and-application-examples-a-746226/?cmp=go-aw-art-trf-SLM_DSA-20180820&gclid=EAIaIQobChMI6v-Inum26gIVTNOyCh2BDwo_EAAYAiAAEgK8DvD_BwE




Advertisement
Advertisement
Advertisement
-
 Difference between a hard link and a symbolic link
Difference between a hard link and a symbolic link -
 Creating and Consuming Static Library in C
Creating and Consuming Static Library in C -
 What is Post-mortem (Incident Report)?
What is Post-mortem (Incident Report)? -
 How object and class attributes work in Python
How object and class attributes work in Python -
 The C preprocessor's Worst abuse - (IOCCC winner, 1986)
The C preprocessor's Worst abuse - (IOCCC winner, 1986) -
 How integers are stored in memory using two's complement in digital computers
How integers are stored in memory using two's complement in digital computers -
 What happens when you type any URL in your browser and press Enter
What happens when you type any URL in your browser and press Enter -
 What is IoT?
What is IoT?